level db如何使用LSM-TREE算法
level db如何使用LSM-TREE算法
来源
Why are keys overlap in SST files at Level 0 in LevelDB system?
Log Structured Merge Trees(LSM) 原理
level db 结构中不同类型的文件
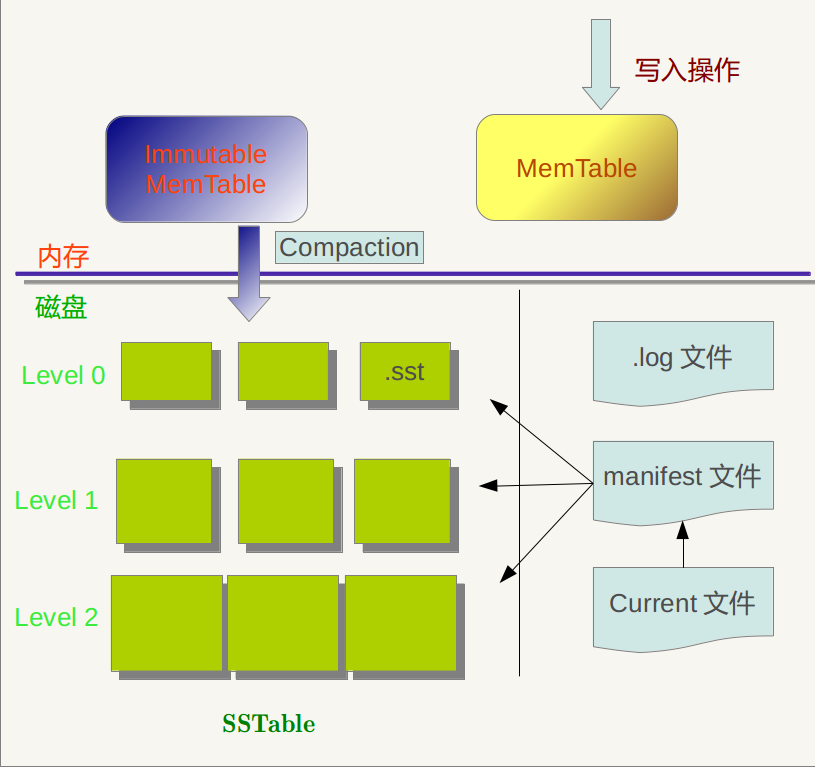
Log files
A log file (*.log) stores a sequence of recent updates. E
A copy of the current log file is kept in an in-memory structure (the memtable). This copy is consulted on every read so that read operations reflect all logged updates.(每次读取都会查阅此副本,以便读取操作反映所有记录的更新。)
Sorted tables
A sorted table (*.ldb) stores a sequence of entries sorted by key.
Manifest
A MANIFEST file lists the set of sorted tables that make up each level, the corresponding key ranges, and other important metadata.
A new MANIFEST file (with a new number embedded in the file name) is created whenever the database is reopened.
The MANIFEST file is formatted as a log, and changes made to the serving state (as files are added or removed) are appended to this log.
Current
CURRENT is a simple text file that contains the name of the latest MANIFEST file.
Info logs
Informational messages are printed to files named LOG and LOG.old.
Others
Other files used for miscellaneous(杂项) purposes may also be present (LOCK, *.dbtmp).
为什么在LevelDB系统中,级别0的SST文件中的键重叠
As is known, keys may be overlap in SST files of level 0 in LevelDB. I am wondering why it needs to be overlap?
An sstable is read-only after being written to the disk from a memtable. Accumulated K/Vs in the log up to a certain size are organized as a memtable and written to the disk as an sstable in level 0.(从memtable将sstable写入磁盘后,它read only。 在日志中累积到一定大小的K/Vs会被组织为一个memtable,并以级别为0的sstable形式写入磁盘)
K/Vs coming in to the log file are not sorted. Hence, a later written sstable in level 0 may have “smaller” keys than keys in previous sstables in level 0.
K/Vs在日志中是无序的,因此新写入得sstable可能和之前的level 0 中已经存在的SST文件中的键重叠
write/updates: 2, 9, 1, 3, 9, 8
sstables in level 0: {1, 2, 9}, {3, 8, 9}
This makes sstables in level 0 written to the disk be “like” a log (append only) which is good for write performance to disks.
From level 1, overlappings are avoided through the process of merging sstables.
如何理解:累积到一定大小的K/Vs被组织成memtable,作为sst able 文件写入到 leve 0
What do you mean by “Accumulated K/Vs in the log up to a certain size are organized as a memtable and written to the disk as an sstable in level 0.”?
- When one KV record is coming for writing, LevelDB would firstly append commit log to Log File (not sorted)
- and then insert this KV record to Memtable (SkipList Insert Operation).
- When Memtable (In sorted orders) achieves the threshold value, it would become the Immutable Table (sorted and read only).
- At last, Immutable Table would be dumped into disk as SSTables. Therefore, KV records in Level0 SSTables are coming from Immutable Table.
为什么level DB可以不断compact,节约空间
level 0 sst 合并压缩到level 1的过程
- Level 0 is not made by compaction
- other levels (except level 0) would be compacted and merged so there are no overlaps in other levels.
举个例子.
- 不断写入产生第一个level 0 sst: sstable file1
write/updates: 2, 9, 1, 3, 9, 8 Immutable Memtable: {1, 2, 3, 8, 9, 9} sstable file 1 in level 0: {1, 2, 3, 8, 9, 9} - 继续不断写入,产生第二个sst: sstable file2
write/updates: 2, 90, 1, 30, 90, 8 Immutable Memtable: {1, 2, 8, 30, 90, 90} sstable file 2 in level 0: {1, 2, 8, 30, 90, 90}
The immutable memtable should be identical to the sstable, or sstable is just a dump of an immutable memtable to disk.
将level 0合并压缩到level1,level1原有1个sstable file3
sstable file1 in level 0: {1, 2, 3, 8, 9, 9}
sstable file2 in level 0: {1, 2, 8, 30, 90, 90}
sstable file3 in level 1: {1, 90}
will be merged to (assume no other sstables to be merged) sstable file4 in level 1
sstable file4 in level 1: {1, 2, 3, 8, 9, 30, 90}
In level 1, there are no other sstables covering key range [1, 90].
使用顺序写代替所有的数据操作代替传统的”读-改-写”.利用了磁盘顺序写来提升程序性能.
在leveldb中,level 0层中的sst文件是由immutable memtable通过后台线程flush得到的,但是由于immutable memtable中的key可能是由重复的,因此在leveldb中level 0的sst文件中key的范围有重叠
其他level层中的sst都是由上层包括本层的sst(key有序)压缩合生成的,因此其他level层的sst文件中的key在自身所在层中不会有重复的。
由于不同level层的ssst文件中的key可能有重复.因此给向下合并压缩提供了操作空间.
LSM-TREE算法
LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。
顺序写的日志策略通常适用于简单场景:
- 数据是被整体访问,像大部分数据库的WAL(write-ahead log)
- 知道明确的offset,比如在Kafka中
另一方面在大量数据中,采用以下算法来加速查询:
- 二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
- 哈希:用哈希将数据分割为不同的bucket
- B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
- 外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件。
所有的方法都可以有效的提高了读操作的性能(最少提供了O(log(n)) ),但是,却丢失了日志文件超好的写性能。上面这些方法,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,所以可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。
更糟糕的是,当我们需要更新hash或者B+树的结构时,需要同时更新文件系统中特定的部分,这就是上面说的比较慢的随机读写操作。这种随机的操作要尽量减少。
所以这就是 LSM 被发明的原理, LSM 使用一种不同于上述四种的方法,保持了日志文件写性能,以及微小的读操作性能损失。本质上就是让所有的操作顺序化,而不是像散弹枪一样随机读写。
写过程
- 当一些更新操作到达时,他们会被写到内存缓存(也就是memtable)中,
- memtable使用树结构来保持key的有序,
- 在大部分的实现中,memtable会通过写WAL的方式备份到磁盘,用来恢复数据,防止数据丢失。
- 当memtable数据达到一定规模时会被刷新到磁盘上的一 个新文件,重要的是系统只做了顺序磁盘读写,因为没有文件被编辑,新的内容或者修改只用简单的生成新的文件
- 越多的数据存储到系统中,就会有越多的不可修改的,顺序的sstable文件被创建,它们代表了小的,按时间顺序的修改。
- 因为比较旧的文件不会被更新,重复的纪录只会通过创建新的纪录来覆盖,这也就产生了一些冗余的数据。
- 所以系统会周期的执行合并操作(compaction)。 合并操作选择一些文件,并把他们合并到一起,移除重复的更新或者删除纪录,同时也会删除上述的冗余。
- 更重要的是,通过减少文件个数的增长,保证读操作的性能。因为sstable文件都是有序结构的,所以合并操作也是非常高效的。
读过程
- 当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,直到key 被找到。
- 因为每个sstable都是有序的,所以查找比较高效(O(logN)),但是读操作会变的越来越慢随着sstable的个数增加,因为每一个 sstable都要被检查。(O(K log N), K为sstable个数, N 为sstable平均大小)。
读优化
读操作是逆序,比顺序的写操作慢很多,可以采用一些算法来加速查询.
- 最基本的的方法就是页缓存(也就是leveldb的 TableCache,将sstable按照LRU缓存在内存中)在内存中,减少二分查找的消耗。
LevelDB 和 BigTable 是将 block-index 保存在文件尾部,这样查找就只要一次IO操作,如果block-index在内存中。一些其它的系统则实现了更复杂的索引方法。
-
即使有每个文件的索引,随着文件个数增多,读操作仍然很慢。通过周期的合并文件,来保持文件的个数,因些读操作的性能在可接收的范围内。合并操作的周期操作会对IO有影响,读操作有可能会访问大量的文件(散乱的读)
-
即便有了合并操作,读操作仍然会访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作,布隆过滤器是一种高效的方法来判断一个sstable中是否包 含一个特定的key。(如果bloom说一个key不存在,就一定不存在,而当bloom说一个文件存在是,可能是不存在的,只是通过概率来保证)
合并算法策略不同
按文件大小合并
- 一些相近大小的文件被合并为一个大文件
- 大量的SST文件被创建
- 在最坏的情况下,所有的文件都要搜索
- 总体的IO次数少
按层合并的策略
- 每一层可以维护指定的文件个数,同时保证不让key重叠。也就是说把key分区到不同的文件。因此在一层查找一个key,只用查找一个文件。(除了LEVEL 0)
- 每次,文件只会被合并到下一层的一个文件。当一层的文件数满足特定个数时,一个文件会被选出并合并到下一层
- 减少在最坏情况下需要检索的文件个数,更好的读性能
- 减小了合并操作的影响
- 减少了空间需求
- 总体的IO次数变的更多