Innodb 逻辑存储结构
Innodb 逻辑存储结构
[TOC]
来源
《mysql技术内幕》
MYSQL存储引擎INNODB详解,从底层看清INNODB数据结构
重要的
- innodb B+树索引本身并不能找到具体的一条记录,能找到只是该记录所在的页。数据库把页载入到内存,然后通过page directory在进行二叉查找具体的记录。
- 数据记录在页中是以堆的形式存放的
- VARCHAR 或者 BLOB 对象大的时候,使用溢出页面存放实际的数据。
整体
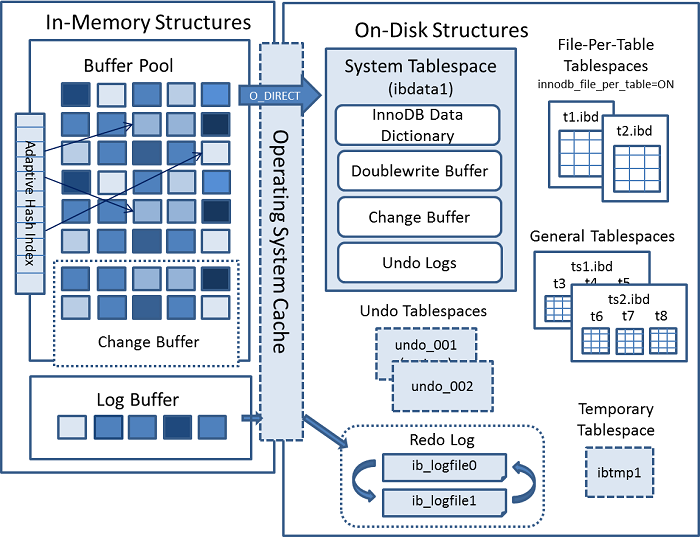
表空间(tablespace)
- 不启用innodb_file_per_table
- all in 共享表空间ibdata1(也可以使用多个文件组成)
- 启用innodb_file_per_table
- 共享表空间
- undo log
- 插入缓冲索引页
- 系统事务信息
- 二次写缓冲(Double write buffer)
- per_table
- 数据
- 索引
- 插入缓冲bitmap页
- 共享表空间
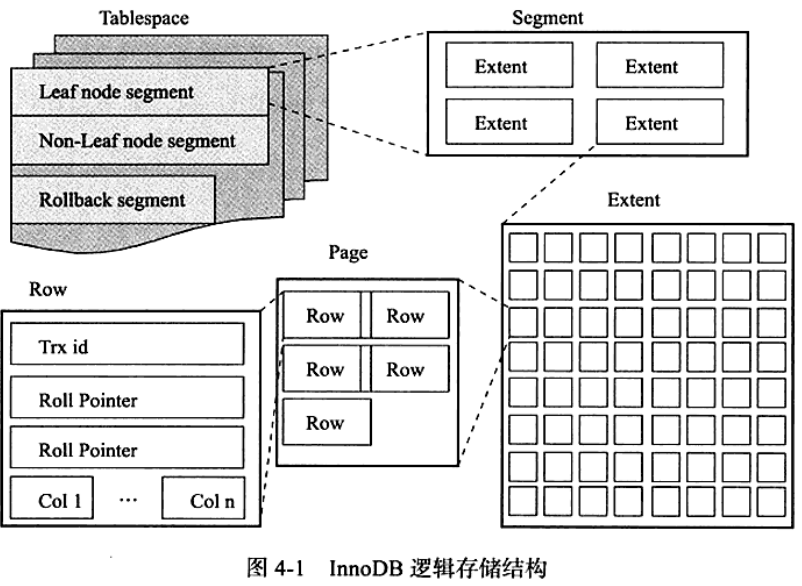
段(segment)
table space由段组成
Innodb存储引擎是index organized,因此索引和数据是一起
常见的段有
- 数据段
B+树的叶子节点
-
索引段
B+树的非索引节点
-
回滚段
区(extent)
MySQL创建表空间的时候,不先申请一整个区,而是先申请一些碎片页(33个)。如果表的空间持续增加,用完所有碎片页以后,才会去申请区。
每个区大小都为1MB
为了保证页的连续性,Innodb每次从磁盘申请4~5个区

页(page)
Innodb中常见的页类型:
- 数据页(B-tree node)
- unod 页(undo log page)
- 系统页(system page)
- 事务数据页(transaction system page)
- 插入缓冲位图页(insert buffer bitmap)
- 插入缓冲空闲列表页(insert buffer free list)
- 未压缩的二进制对象页(uncompressed blob page)
- 压缩的二进制对象页(compressed blob page)
行(row)
InnoDB 是MySQL 的一种面向行(row-oriented)存储引擎
行记录格式
barracuda_file_format #新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED 和 DYNAMIC
├── antelope_file_format#它最开始并没有名字;Antelope 的名字是在新的文件格式 Barracuda 出现后才起的。它支持两种行格式:COMPACT 和 REDUNDANT
│ ├── compact# mysql5.0引入。一个页中存放的行数据越多
│ └── redundant#
├── compressed
└── dynamic
compact格式
| variable length header | null Indicator | recorD header | row ID | transaction id | roll pointer | column1 | column2 |
|---|---|---|---|---|---|---|---|
| 变长字段长度列表(2字节) | 该行数据是否有NULL值(1字节) | 记录头信息(5字节) | 【隐藏列】6字节 | 事务Id【隐藏列】6字节 | 回滚指针,指向这行数据的上一个版本。【隐藏列】7字节 | col数据1 | col数据2 |
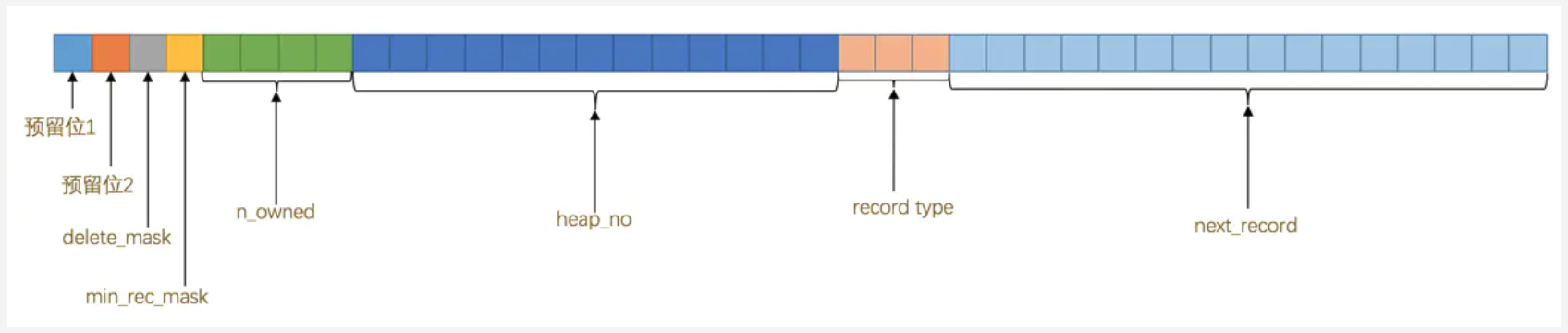
记录头信息(5字节,40bit)
redundant格式
| length offset list | recorD header | row ID | transaction id | roll pointer | column1 | column2 | column3 |
|---|---|---|---|---|---|---|---|
| 字段长度偏移列表(1 or 2字节) | 记录头信息(6字节) | 【隐藏列】6字节 | 【隐藏列】7字节 | col数据1 | col数据2 | col数据3 |
create table z(
a int not null,
b int null,
c int not null,
d int not null,
unique key(b),
unique key(d),
unique key(c),
)
insert into z select 1,2,3,4;
insert into z select 5,6,7,8;
insert into z select 9,10,11,12;
select a,b,c,d,_rowid FROM z;
+---+------+----+----+--------+
| a | b | c | d | _rowid |
+---+------+----+----+--------+
| 1 | 2 | 3 | 4 | 4 |
| 5 | 6 | 7 | 8 | 8 |
| 9 | 10 | 11 | 12 | 12 |
+---+------+----+----+--------+
3 rows in set (0.00 sec)
建表时,如果没有显示得定义主键,innoDB将选择建表时第一个定义的非空唯一索引为主键。如果不符合上述条件,Innodb自动创建一个6直接指针指向它。
- 建表时,没有显示得定义主键
- 非空唯一索引
- 索引定义顺序
行溢出数据
mysql中磁盘与内存交互的基本单位是页,一般为16KB,16384个字节,而一行记录最大可以占用65535个字节,这就造成了一页存不下一行数据的情况
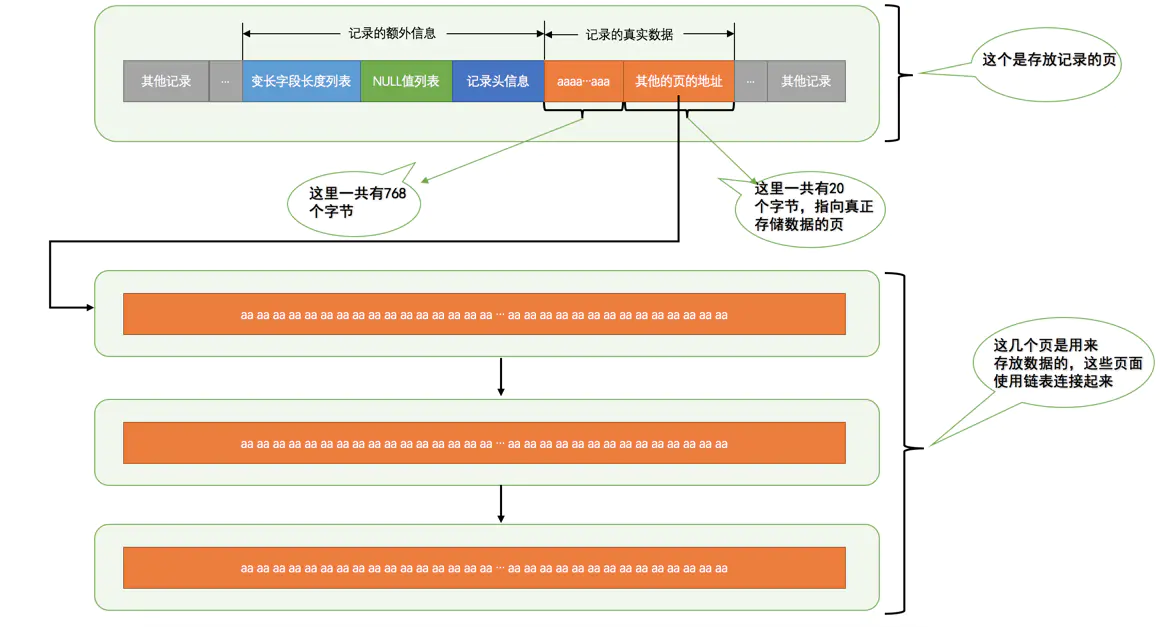
当 使用 Compact 或者 Redundant 格式存储极长的 VARCHAR 或者 BLOB 这类大对象
- 不会直接将所有的内容都存放在数据页节点
- 将行数据中的前 768 个字节存储在数据页中
- 后面会通过偏移量指向溢出页
当使用新的行记录格式 Compressed 或者 Dynamic 时
- 都只会在行记录中保存 20 个字节的指针
- 实际的数据都会存放在溢出页面中。
MySQL中规定一个页中至少存放两行记录
* 每个页除了存放我们的记录以外,也需要存储一些额外的信息,大概132个字节。
* 每个记录需要的额外信息是27字节。
假设一个列中存储的数据字节数为n,如要要保证该列不发生溢出,则需要满足:
132 + 2×(27 + n) < 16384
char 的行结构存储
使用的字符集不同,char类型列本部存储的可能不是定长的数据。
utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多文本平面。
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。
- latin1 单字节
- utf-8 char(10) 最少可以存储10字节的字符,最大可以存储30字节的字符。
- MySQL LENGTH(str) 函数的返回值为字符串的字节长度,使用 uft8(UNICODE 的一种变长字符编码,又称万国码)编码字符集时,一个汉字是 3 个字节,一个数字或字母是一个字节
- MySQL CHARACTER_LENGTH() returns the length of a given string. The length is measured in characters.
MariaDB [test]> create database hui_test;
Query OK, 1 row affected (0.027 sec)
MariaDB [test]> use hui_test;
Database changed
MariaDB [hui_test]> create table test_char(
-> c1 char(4)
-> )charset='gbk';
Query OK, 0 rows affected (0.354 sec)
MariaDB [hui_test]> insert into test_char values('我们');
Query OK, 1 row affected (0.039 sec)
MariaDB [hui_test]> insert into test_char values('abc');
Query OK, 1 row affected (0.002 sec)
MariaDB [hui_test]> select length(c1),character_length(c1),c1 from test_char;
+------------+----------------------+--------+
| length(c1) | character_length(c1) | c1 |
+------------+----------------------+--------+
| 4 | 2 | 我们 |
| 3 | 3 | abc |
+------------+----------------------+--------+
2 rows in set (0.036 sec)
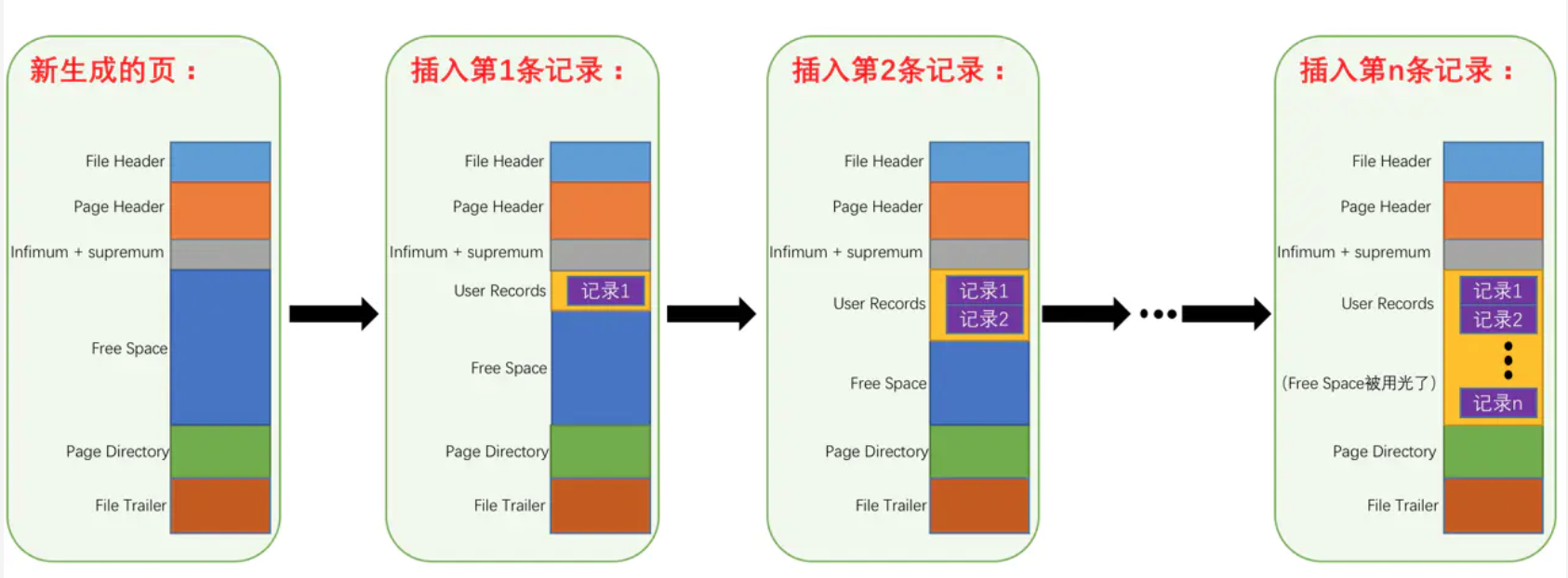
数据页结构
一个 Innodb 页有以下七个部分:
| fil header | page header | infimum superemum | user records | free space | page directory | file trailer |
|---|---|---|---|---|---|---|
| 文件头(38字节) | 页头(56字节) | 字符串形式的“ Infimum”代表开头,“Supremum”表示结尾 | 与infimum列一起即行记录 | 空闲空间 | 页目录 | 文件结尾信息(8字节) |
user records, free space, page directory为实际的行记录存储空间,因此大小是动态的
fil header
| Name | Size | Remarks |
|---|---|---|
FIL_PAGE_SPACE |
4 | 4 ID of the space the page is in。(同一个文件可能有不同的页属于不同的表空间) |
FIL_PAGE_OFFSET |
4 | ordinal page number from start of space 表空间中页的偏移值 |
FIL_PAGE_PREV |
4 | offset of previous page in key order当前页的上一页 |
FIL_PAGE_NEXT |
4 | offset of next page in key order当前页的下一页 |
FIL_PAGE_LSN |
8 | log serial number of page’s latest log record 代表改页最后被修改的日志序列位置LSN。 |
FIL_PAGE_TYPE |
2 | 页的类型 |
FIL_PAGE_FILE_FLUSH_LSN |
8 | “the file has been flushed to disk at least up to this lsn” (log serial number), valid only on the first page of the file |
FIL_PAGE_ARCH_LOG_NO |
4 | the latest archived log file number at the time that FIL_PAGE_FILE_FLUSH_LSN was written (in the log) |
Page Header
The Page Header has 14 parts, as follows:
| Name | Size | Remarks |
|---|---|---|
PAGE_N_DIR_SLOTS |
2 | number of directory slots(槽) in the Page Directory part; initial value = 2 |
PAGE_HEAP_TOP |
2 | record pointer to first record in heap。(指向堆的第一个记录的指针,记录在页中是以堆的形式存放的) |
PAGE_N_HEAP |
2 | number of heap records; initial value = 2(堆中的记录数) |
PAGE_FREE |
2 | record pointer to first free record |
PAGE_GARBAGE |
2 | “number of bytes in deleted records”(即行记录结构中delete flag为1的记录大小的总数) |
PAGE_LAST_INSERT |
2 | record pointer to the last inserted record(最后插入记录的位置) |
PAGE_DIRECTION |
2 | either PAGE_LEFT, PAGE_RIGHT, or PAGE_NO_DIRECTION (最后插入的方向) |
PAGE_N_DIRECTION |
2 | number of consecutive inserts in the same direction, for example, “last 5 were all to the left”(一个方向连续插入记录的数量) |
PAGE_N_RECS |
2 | number of user records(该页中记录的数量) |
PAGE_MAX_TRX_ID |
8 | the highest ID of a transaction which might have changed a record on the page (only set for secondary indexes)(修改当前页的最大事务ID) |
PAGE_LEVEL |
2 | level within the index (0 for a leaf page) (页在当前索引页的位置。0x00代表叶节点) |
PAGE_INDEX_ID |
8 | identifier of the index the page belongs to(当前页属于哪个索引) |
PAGE_BTR_SEG_LEAF |
10 | “file segment header for the leaf pages in a B-tree” (this is irrelevant here) |
PAGE_BTR_SEG_TOP |
10 | “file segment header for the non-leaf pages in a B-tree” (this is irrelevant here) |
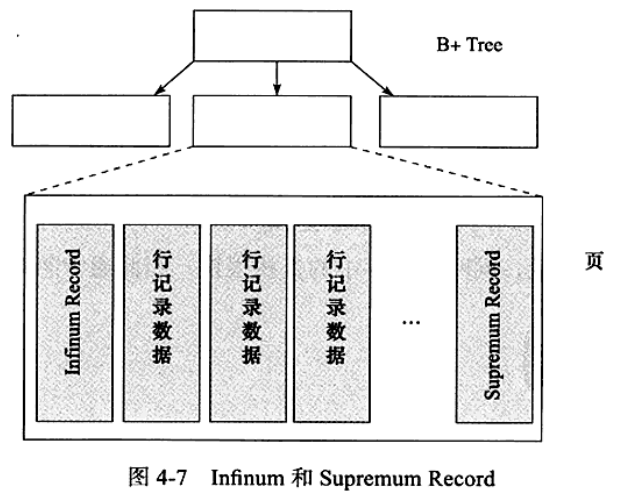
infimum and superemum
每个页有两个虚拟的行记录,用于限定记录的边界。infimum记录是比该页中所有主键值都要小的值,superemum记录是比该页中所有主键值都要大的值
Free space
链表结构,在一条记录被删除后,该空间会被加入到空闲链表中。
Page Directory
Page Directory(页目录)中存放了记录的相对位置(页相对位置,而不是偏移量),有时候这些记录指针成为Slots(槽)或者目录槽(Directory Slots)。【感觉类似于linux逻辑地址和物理地址使用】
- B+树索引本身并不能找到具体的一条记录,能找到只是该记录所在的页。
-
数据库把页载入到内存,然后通过page directory在进行二叉查找
- 由于innodb中Page Direcotry是稀疏目录,二叉查找只是个粗略的结果,因此Innodb存储引擎必须通过
recorder header中的next_record来继续查找相关记录。
FIle Trailer
为了检测页是否已经完整写入磁盘
- 前4字节代表该页的checksum
- 后4字节和File Header中的FIL_PAGE_LSN相同
mysql5.6.6版本开始新增参数innodb_checksum_algorithm,该参数用来控制检测checksum函数的算法,默认为crc32。