mysql调优带来的启示
调优要抓住关键点.缓存也有缓存的弊端.如何让缓存价值更高.硬件层面解决问题.
进行 mysql 管理优化,三大原则
- 访问内存数据的速度比访问磁盘数据速度快
- 将数据保存在内存里,尽可能减少磁盘活动
- 保留索引的信息比保留行的内容重要
调优的基本方式
- 一次只改一个参数.如果同时修改多个变量,则很难对每个更改所产生的影响进行评估
- 逐步增大系统变量值.
- 避免一下子耗光系统资源
- 避免系统因为你将变量设置过高而变得异常快或者异常慢
- 不要在生成环境做测试
- 禁用不需要的存储引擎.减少内存使用.
- 保持简单的访问权限.在 MySQL 数据库中,权限表除了 user 表外,还有 db 表、tables_priv 表(对单个表进行权限设置)、columns_priv 表(对单个数据列进行权限设置)和 procs_priv 表(对存储过程和存储函数进行权限设置).当配置它们时,服务器在检查 sql 语句权限时,一定会检查它们的内容.
一般调整的通用型系统变量
- back_log
在处理当前连接时,排队等待连接的最大请求数.
-
max_connections
服务器支持的最大客户端并发连接数.可以使用
show status查看变量Max_used_connections -
table_open_cache
当服务器打开文件时,会试图将它们保持在打开状态,以减少必须要完成的文件打开操作和文件关闭操作的数量.可以通过
show global status like 'Opened_tables'进行评估- 如果
Opened_tables迅速增大,则意味缓存太小 - 大一点的缓存可以减少缓存失效
- 如果
- table_definition_cache
与table_open_cache正相关,用于控制存储表定义的缓存大小.
-
open_files_limit
- 考虑操作系统对进程所用使用的文件句柄限制
- mysql 本身也有自己的open_files_limit限制
- max_allowed_packet
客户端通信的缓存区的最大值.默认 1MB ,允许的最大值为 1GB.可能还需要相应的增大 下面两个变量
- read_buffer_size 读取操作使用的缓冲区大小
-
sort_buffer_size 排序操作使用的缓冲区大小
每一个 session 都会受其影响,应该要逐步调整
innodb 缓冲池
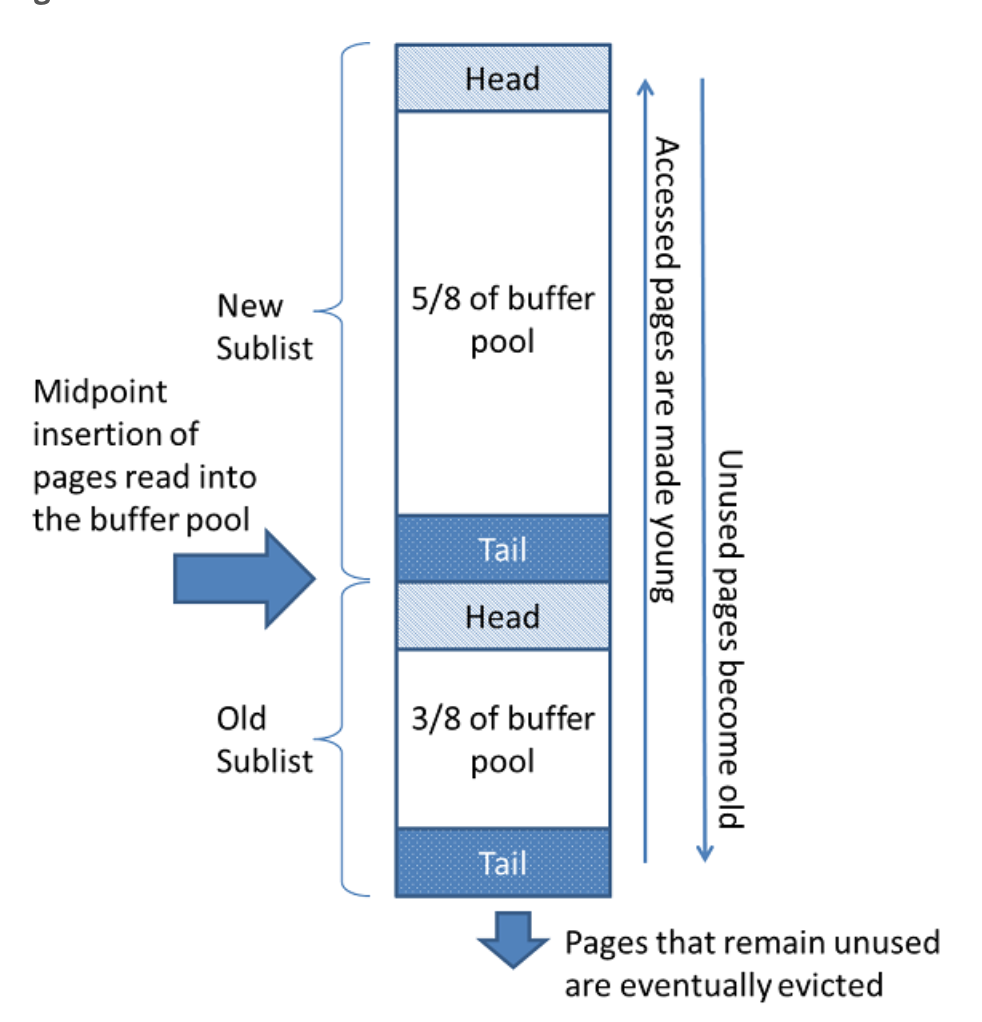
基本组成
- 是个列表,并且分新旧两个子列表
- 改进的 LRU 策略,插入数据插入到旧的子列表前
- 如果数据块是查询需要的,会被访问后移到新子列表前面
- 如果是由于预读需要,可能不会被访问,减少了预读对缓存的影响
一般调节的参数
- innodb_buffer_pool_size
缓冲池大小.单位为字节
-
innodb_buffer_pool_instance
如果innodb_buffer_pool_size>=1GB && innodb_buffer_pool_instance>1,Innodb 会把缓冲池处理成多个小的缓冲池实例.通过随机分配的方式,减少并发竞争.
-
影响缓冲池缓存失效的参数
- innodb_old_blocks_pct 缓冲池的旧子列表所占的百分比.默认是 37.
- innodb_old_blocks_time 一个缓存块在第一次访问之后,下次访问之前,需要在旧子列表待多少毫秒才移动到新子列表.(将其设置为大于 0,可以防止类似表扫描这种一次性访问大量数据的行为对缓冲池产生太大影响)
考虑开启 mysql 查询缓存
- select 语句执行后,服务器会记住这条查询语句的文本和它返回的结果
- 查询缓存通过比较查询语句的文本进行比对,是否命中缓存
- 查询返回的结果不确定则不会存储.例如使用时间 NOW()函数.
- 表被修改,指向它的所有缓存查询都失效
弊端
- 为查询缓存分配过大的内存,会导致比较当前查询语句是否命中缓存花费过多时间.
- 多客户端连接情况下,带来了并发的缓存竞争.(因为查询缓存只能单线程操作)
硬件
- 更多内存
- 更强,更多处理器
- 使用更快的硬盘
- 全用 ssd
- 利用机械盘组成 raid
- 将磁盘活动分布到不同的物理设备上,充分利用并行特性