记录文章-备份领军产品DataDomain
文章来源
传统磁带优势
- 磁带相对于磁盘介质而言,具有很好的价格优势
- 备份存储主要是顺序写操作,只有在数据恢复的时候,才需要从磁带上读取数据
硬件革新带来新的备份存储
- 得益于巨磁阻技术的发展,磁盘容量在近几年一直高歌猛进
- 内存价格下降
- cpu计算能力上升
在这次革命的引领中,DataDomain算是一个非常成功的革命者。DataDomain的成功源自于将磁盘存储技术成功的应用于备份领域.
DataDomain是一种目的端数据去重的设备
开创磁盘备份的新模式

从上图中我们可以知道,在整个IT结构中,Primary Storage的数据通过备份服务器进行数据备份,或者通过Archive服务器进行数据归档操作。备份和归档的存储介质通常是磁带。
DataDomain设备的出现正好是替代了传统磁带的位置,从而使得Primary Storage的数据直接或者通过备份服务软件备份到DataDomain设备。DataDomain设备无论在性能还是在数据去重效率方面都是首屈一指的,可以说DataDomain开创了磁盘备份的新模式。
磁带的弊端
- 传统的带库体积庞大,需要采用机械手装置加载磁带。
- 由于磁带本身不具备随机读写能力,因此,在顺序写的情况下表现尚可,但是,一旦需要随机读取时,就显得非常力不从心。
- 另外,磁带存储管理非常麻烦,占用大量的空间。
DataDomain设备优势
- 所有应用的数据都可以通过备份服务器备份至DataDomain的设备
- 多台DataDomain设备之间并且可以进行远程数据复制,从而可以提高数据的容灾水平。
- 当数据需要进行长期保存时,DataDomain设备提供了Archive的功能,可以将备份数据封存起来,进行长期存放。
重复数据删除
DataDomain在引入磁盘备份的时候,引入了一个非常重要的核心技术:重复数据删除。
其实,在那个年代,Datadomain不是唯一一家针对备份领域从事磁盘备份的厂商,也不是唯一一家从事重复数据删除的备份厂商。但是,DataDomain如今是单机性能最佳,市场占有率最高的基于重复数据删除的磁盘备份厂商。这其中的原因是为什么呢?
在线重复数据删除对硬件要求
- 需要很强的CPU能力
- 很强的随机IO读写能力
块级重复数据删除的原理
- 首先将输入数据进行自动分段,自动分段的目的在于实现变长数据块,提高重复数据删除效率。
- 得到分段块之后,对这个数据块计算一个HASH值,具体算法可以采用SHA1。这个HASH值可以被称之为这个数据块的Fingerprint(指纹)
- 当得到这个数据块的指纹信息之后,需要在当前系统内查找是否存在与其匹配的指纹信息,如果能够找到匹配的指纹,说明当前系统中已经存储了输入的数据块,那么可以直接丢弃该输入数据块,不进行存储;反之,需要需要将输入数据块写入存储系统中,进行持久化保存
解决小概率的hash冲突
如果不同的数据存在相同的指纹信息怎么办?
业内一般解决方案
- 一种是再为数据块计算一种HASH值或者校验码,当指纹信息匹配之后,还需要校验信息完全匹配。从概率的角度来看,不同的数据块具有相同的指纹信息和校验信息是不可能的,通过这种方式可以有效避免HASH碰撞。
- 一种方法是直接将数据读出来进行比对,这种方法会产生很多的额外的IO请求,对系统的性能产生极大的影响。
DD解决方案
备份系统,具有很好的IO Pattern。基本上都是顺序IO操作,并且在备份过程中基本上都是写操作,即使有读操作,其和写操作也具有很强的IO局部性。DataDomain基于这种IO Pattern做了很好的规避.
破除磁盘瓶颈点
基于磁盘做重复数据删除是有挑战的,最大的挑战在于如何快速的进行重复数据查找。
传统磁盘一个最大的问题在于随机读写能力差。而磁盘级的数据查找就需要磁盘具有很强的随机读写能力。
传统硬盘解决方案:磁盘集群
很多厂商在解决这个问题的时候采用了“磁盘集群”的思路。一块磁盘的能力是有限的,多块磁盘聚合起来的随机访问能力就可以达到数据查找的要求。基于此,在DataDomain创业的年代,这是很多厂商选择的技术路线。用磁盘的聚合效应来达到重复数据删除所需要的性能要求。
DD解决方案
DataDomain没有采用这种技术路线。而是采用了另一种高性能计算节点的技术路线。其典型的思想是采用NUMA计算架构,采用高性能处理器构成重复数据删除控制器。由于采用了NUMA架构,因此,整个控制器可以管理容量很大的内存空间,可以做到90%以上的fingerprint信息缓存在内存中。因此,磁盘级的重复数据查找转变成了内存查找。和其他设计相比,这是一个硬件架构的革新。采用这个架构,还有一个好处就是可以随着CPU处理能力的增强而不断提升重复数据删除的性能。所以,从下图可以看出,DataDomain的产品可以在很少disk的情况下可以达到更好的数据吞吐量。
SISL (Stream Informed Segment Layout)
在软件设计上,DataDomain提出了SISL (Stream Informed Segment Layout)的设计思路,这也是一种面向数据备份领域的软件创新。正是因为这种创新,使得DataDomain具有更好的吞吐量。
SISL的创新点在于DataDomain发现了不同的备份数据流之间具有很强的相关性,或者说是局部性。两次备份数据流之间也许存在相同的磁盘访问局部性。就是因为发现了这种局部性,数据在磁盘上的存放就应该和Stream相关,这样才可以最大可能的避免磁盘抖动引入的性能问题,可以将磁盘性能发挥到极致。
优化内存查找
前面提到DataDomain将磁盘查找转换成了内存查找操作,因此,内存查找反而成了整个系统性能瓶颈点。为了缓解内存查找问题,软件设计过程中采用了Cache、Summary Vector等技术手段,减少内存查找次数。较为详细的论文可以参考:《Avoiding the Disk Bottleneck in the Data Domain Deduplication File System》
全局文件消重文件系统DDFS
完成DataDomain重复数据删除的核心模块是DDFS,该模块本质上是完成了块级重复数据。
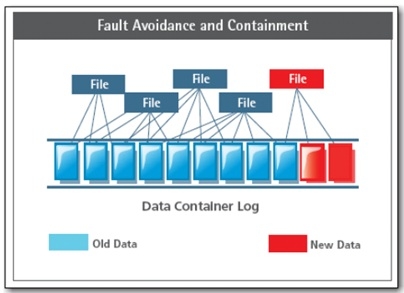
一个文件可以表示成多个块的物理组合。重复数据删除的单元就是文件所管理的块。DDFS是一个文件系统,因此其具有完备的Name Space管理、文件管理。又因为其是一个重复数据删除的系统,因此,和其他文件系统相比多了一层重复数据删除。由于DataDomain系统定位备份领域,备份领域的IO Pattern以写为主,因此,Log Structured文件系统是一种非常适合的高效实现方式。通过上图可以看出,DDFS采用了Log写的方式,其引入的问题是需要进行脏块回收(GC),并且对读过程有一定的性能影响。
下图是DDFS的结构框图:
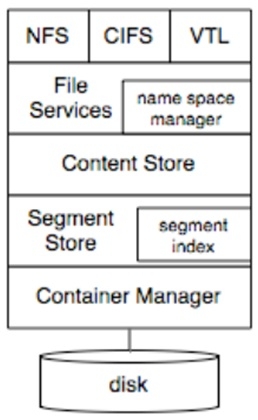
从上图可以看出,其主要分为如下几层:
- 导出协议层。整个设备可以采用NFS、CIFS或者VTL的协议对外导出。其实,DataDomain比较高效的导出方式是DD-Boost,采用DD-Boost标准可以大大提升整体性能。在导出协议层需要考虑网络等因素引入的延迟问题。
-
File Service。该层主要进行文件的Namce Space管理,并且将输入数据传递给Content Store层进行处理。在这一层需要考虑snapshot、checkpoint等问题。
-
Content Store层。在该层进行数据流的切分,采用Anchor算法进行动态数据块分割,并且计算数据块的HASH值。这个被划分的数据块被称之为Segment。
-
Segment Store层。该层最主要的任务就是查找输入Segment的fingerprint是否已经在系统中存在。这一层的工作就是重复数据删除。如果没有被删除的数据,那么需要继续写入下一层Container。
-
Container Management层。这一层主要管理segment的存储。为了保证数据可靠性,所有数据都被写入RAID进行保存,为了避免RAID引入的写放大问题,Container这一层需要与RAID进行配合。并且为了实现端至端的数据完整性,DataDomain引入了具有专利保护的DIA机制。
CPU-Centric存储系统
重复数据删除的一个最大问题在于磁盘的性能瓶颈。对于输入数据需要计算指纹信息,然后在整个系统中需要匹配这个指纹信息,这时就会涉及到磁盘的随机读操作。一旦引入磁盘随机读,那么整体的IO性能就会大为下降。这个问题就是重复数据删除面临的最大Challenge。
为了解决这个问题,很多厂商走的技术路线是增强磁盘的随机读性能,通过磁盘的并发读能力来缓解这个问题。而DataDomain并没有走这条技术路线,他走的是避免磁盘读、磁盘查找这样一个技术路线。
CPU等Platform的性能提高,DataDomain在2008年之后,整体Throughput呈现爆发式增长,并且公司收入也随着性能的提高跨越式增长。
- DataDomain是一个通过CPU性能来换取存储性能的一个解决方案。DataDomain的很多技术瓶颈点都在于CPU,而不在于RAID/Disk方面的性能瓶颈,这点和其他厂商的存储产品是完全不同的。
- DataDomain可以采用CPU换存储的技术路线也得益于存储领域特殊的IO Pattern。在备份领域都是大读大写,并且在备份的时候都是顺序写。如果将这种思路应用到Primary Storage领域,那么这种情况将会有所变化,将会有新的问题出现。因此,DataDomain一直定位于备份/数据保护市场。
-
DataDomain的系统通过将所有的Fingerprint信息缓存在内存中,然后通过CPU在内存中查找重复数据,避免在磁盘上进行数据搜索。当一个系统的存储容量很大的时候,那么需要巨大的内存容量,因此DataDomain的系统一定是一个支持大内存的NUMA系统,并且一定是一种采用定制硬件的方式出现。
采用这种方式之后,内存容量大小就决定了存储容量。如果需要支持更大的存储容量,那么需要更大的内存支持,因此一种型号的机器,会有一个存储容量上限。从李凯演讲稿中可以看出,从2008年之后,DataDomain的单机系统可以支持48TB容量,之后几年容量增长很快,这都得益于NUMA架构内存容量的增长。
数据无损体系结构
在DataDomain的产品中有一个非常值得一提的技术是DIA,这一点在DataDomain的销售中一定是要提的一个特性。什么是DIA,其实就是端至端的一种数据保护体制。备份系统基本上是数据的最后一站,对于存储于备份系统中的冷数据而言,归档系统是他的最后栖息之地。DataDomain是备份归档一体化的系统。因此,数据存储可靠性就显得尤为关键和重要。
磁盘属于一种易损部件,其是一种机械装置。通常来讲磁盘的使用寿命是5年,在这样一中并不可靠的介质上如何构建可靠存储系统呢?这是DataDomain需要考虑的问题。为了达到这样的一个目的,无论是文件系统还是磁盘阵列RAID都做了很多独到的设计。例如,如果DataDomain的RAID6发生3块盘故障的情况,那么其磁盘上的数据还可以在offline的情况下进行恢复,这是很多其他RAID所做不到的。
在有了RAID保护下的磁盘,也许还会存在HBA问题、磁盘的Silent corruption 、驱动软件等问题,如何解决上述这些问题呢?DataDomain引入了端至端的数据保护技术,但是并没有采用T10的标准,而是一套自己的数据校验机制。通过这种机制,存入磁盘的数据保证是有效、可靠的。当然对于Silent Corruption的问题,还需要其他机制的支持,例如Scrub。
高效远程数据复制
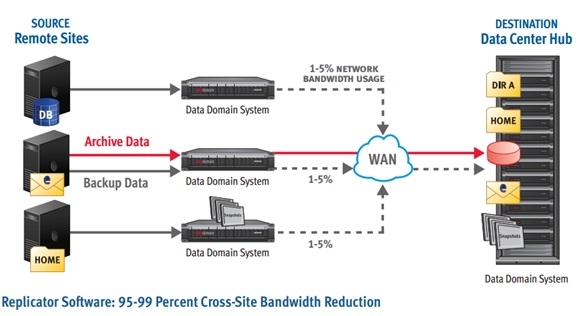
DataDomain的产品支持远程数据复制的功能。对于一个存储系统而言,这个功能属于标配,没有远程数据复制的功能,那么客户就会无法保证其数据的可靠性。DataDomain的远程数据复制功能比较强大,可以支持广域网内的数据复制,多个节点上的数据可以直接复制到远程的同一个设备上。并且可以支持一个客户级别(Mtree)的数据复制、一个dedupe域级别的远程数据复制和系统级别的数据复制。远程数据复制的结构如下图所示:
挑战
-
DataDomain面临的市场格局也慢慢发生了变化,例如云备份的兴起,以虚拟化技术为主导的数据中心的兴起,大数据的热潮。Datadomain面临着更多的压力
-
Scale-out等架构上新的需求会对DataDomain形成新的挑战