笔记_CPU缓存知识
记录一下 cpu cache 相关内容
主要来自于COOLSHELL – 与程序员相关的CPU缓存知识,有些是以下几篇文章:
- cache相关概念及工作原理介绍
- CPU总线
- Cache Addressing: Length of Index, Block offset, Byte offset & Tag?
- Cache直接映射、组相连映射以及全相连映射
- 缓存一致性协议
存储器分层结构
存储器分层次结构: L1 L2 cache cpu 核独占,L3 cache 多核cpu 共享.
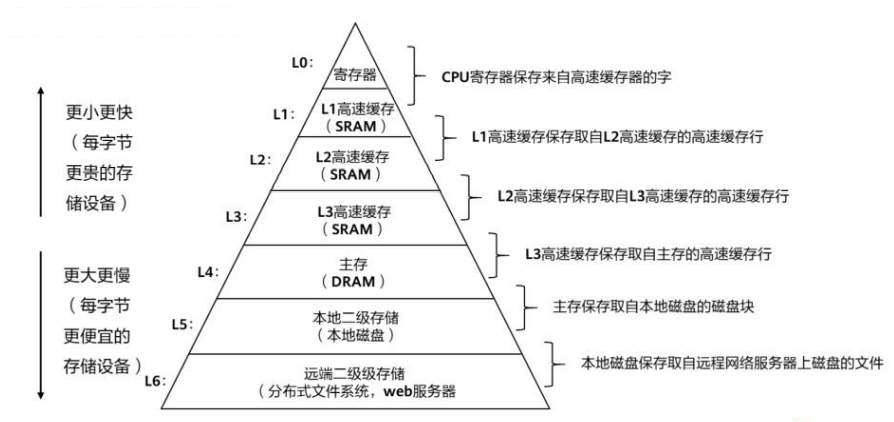
cpu 寄存器速度远快于主存 DRAM,如果没有 cpu cache ,cpu 性能将严重受限于主存.
cpu 缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。
这种局部性既包括
- 空间局部性(Spatial Locality)
- 时间局部性(Temporal Locality)
存储器的分层结构,带来了性能问题
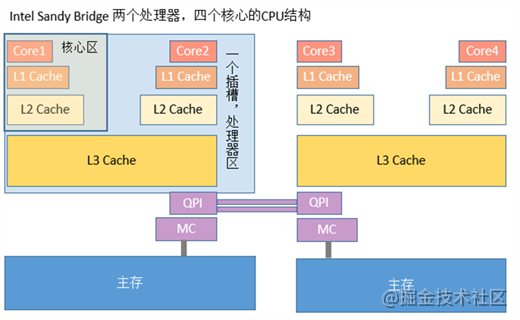
现代服务器都是 一个节点有多个多核 cpu.
cpu l1 l2 cache 是独享的,l3 cache 是多核共享的,其它是所有 cpu 共享的,这带来了数据一致性的问题.
等同一个分布式系统,只是不需要考虑网络问题.
字(Word)
一般以8位二进制作为一个储存单元,也就是一个字节。每个单元有一个地址,是一个整数编码,可以表示为二进制数。
- 总线一般被设计来传输固定大小的一块数据,这块数据被称为字(word)
- 对于一个64位的CPU,其数据总线宽度为64位,一次拥有取出8个字节数据的能力.
- 64 位的CPU => 1 字=8 字节
- 32 位的CPU => 1 字=4 字节
- 问一个字占多少字节是没有意义的,因为字的大小取决去具体系统的总线宽度.
总线
总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是由导线组成的传输线束。
按照计算机所传输的信息种类,计算机的总线可以划分为:
- 数据总线 => 传输数据信号
-
地址总线 => 传输地址信号
-
控制总线 => 传输控制信号

cpu 如何读取数据
cpu(32bit)发送读/写内存的请求后,会被cache控制器截获。
cache控制器根据截获的请求地址,将其分为标签域、组索引域、数据索引域。然后做了三部分工作:
- 将控制器标签域的值与存储器目录存储段cache-tag比较.查看是否有相应的存在:
- 如果存在,首先通过组索引域确定具体的cache行(cache line)。
- 然后根据标签域中的状态位确定行是否有效.
- 有效则为命中(hit).
- 命中后,再根据数据索引域确定cache行中的具体字,
- 进行对应的读/写操作(具体的写操作由写策略决定)。
- 无效则为失效(miss).
- 如果不存在,则为失效(miss).
- 失效后控制器从主存中拷贝整个cache行的数据到存储器的某个cache行中
- (具体选择哪个行是替换策略决定,何时进行替换由分配策略决定)
缓存替换策略
直接映射
抽象结构如下

- 结构上,一个直接映射(Direct Mapped)缓存由若干缓存块(Cache Block,或Cache Line)构成.
- 每个缓存块存储具有连续内存地址的若干个存储单元
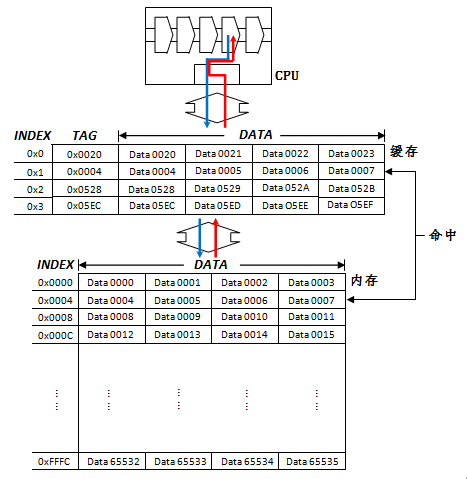
(注意内存左侧给出的地址是字地址而不是字节地址,)
这个缓存共有四个缓存块,每个块16字节,即4个字,因此共有64字节存储空间。使用写回(Write back)策略以保证数据一致性。(32位操作系统,1个字等于4个字节,32bits)
此时处理器请求的地址在0x0020~0x0023之间,或在0x0004~0x0007之间,或在0x0528~0x052B之间,或在0x05EC~0x05EF之间,均会命中L0 cache.
将地址由高至低划分为四个部分:标签、索引、块内偏移、字节偏移。
(左边是高位,右边是低位位)
| 字的地址 | |||
|---|---|---|---|
| Number of tag bits | Number of index bits | Number of block or line offset bits | Number of byte offset bits |
| 1. 地址长度减去用于偏移量和索引的位数。 2.可以使用主存储器的大小来计算地址的长度 |
1.每个缓存块有一个索引(Index) 2.它一般是内存地址的低端部分 3.但不含块内偏移和字节偏移所占的最低若干位 4.log2(CS), where CS is the number of cache sets. |
log2(words per line) 例子里:每个块=16字节=4个字 log2(4)=2 |
1. => 0 for word-addressable memory b. => log2(bytes per word) for byte addressable memory |
拼接标签值和此缓存块的索引 => 缓存块的内存地址 cache line 地址
如果再加上块内偏移,就能得出任意一块数据的对应内存地址 => 块内某个字的地址.
如果再加上字节偏移, 就能得出任意一个字节的对应内存地址.
Number of index bits
- 对于Direct Mapped,CS等于CL,即高速缓存行的数量,因此索引位的数量为log2(CS)= log2(CL)。
因为通过取模计算,定位 cache line. 从 cache line 定位具体
字 -
对于完全关联,CS为1。由于log2(1)为0,因此没有索引位。
-
对于n向关联CS = CL÷n:log2(CL÷n)索引位。
过程
系统启动时,缓存内没有任何数据。之后,数据逐渐被载入或换出缓存。
假设在此后某一时间点,缓存和内存布局如上图所示。
此时,若处理器执行数据读取指令,控制逻辑依如下流程:
- 用索引定位到相应的缓存块
-
用标签尝试匹配该缓存块的对应标签值。
-
如命中,用块内偏移将已定位缓存块内的特定数据段取出,送回处理器。
-
如未命中,先用此块地址(标签+索引)从内存读取数据并载入到当前缓存块,再用块内偏移将位于此块内的特定数据单元取出,送回处理器。
这里要注意的是:
-
读入的数据会冲掉之前的内容。为保证数据一致性,必须先将数据块内的现有内容写回内存。
-
尽管处理器请求的只是一个字,缓存仍必须在读取的时候把整个数据块都填充满。
-
缓存的读取是按缓存块大小为边界对齐的。
对于大小为16字节的缓存块,任何因为0x0000、或0x0001、或0x0002、或0x0003造成的未命中,都会导致位于内存0x0000—0x0003的全部四个字被读入块中。
而处理器执行数据写入指令时,控制逻辑依如下流程:
- 用索引定位到相应的缓存块。
- 用标签尝试匹配该缓存块的对应标签值。其结果为命中或未命中。
- 如命中,用块内偏移定位此块内的目标字。然后直接改写这个字。
- 如未命中,依系统设计不同可有两种处理策略,分别称为按写分配(Write allocate)和不按写分配(No-write allocate)。
- 如果是
按写分配,则先如处理读未命中一样,将未命中数据读入缓存,然后再将数据写到被读入的字单元。 - 如果是
不按写分配,则直接将数据写回内存。
- 如果是
一个数据总量为4KB、缓存块大小为16B的直接映射缓存一共有256个缓存块,其索引范围为0到255。
使用一个简单的移位函数,就可以求得任意内存地址对应的缓存块的索引。
由于这是一种多对一映射必须在存储一段数据的同时标示出这些数据在内存中的确切位置。
- 所以每个缓存块都配有一个标签(Tag)。
- 拼接标签值和此缓存块的索引,即可求得缓存块的内存地址。
- 如果再加上块内偏移,就能得出任意一块数据的对应内存地址。
- 因此,在缓存大小不变的情况下,缓存块大小和缓存块总数成反比关系。
优点
直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。
缺点
Cache的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
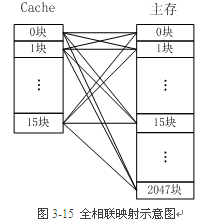
全相联映射
这种相联完全免去了索引的使用,而直接通过在整个缓存空间上匹配标签进行查找。 由于这样的查找造成的电路延迟最长.
优点
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。
缺点
但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用
组相联映射
组相联映射实际上是直接映射和全相联映射的折中方案
下面图展示2way 组相联. cache 中 两块为一组(如:块 0和块 1, 块 2 和块 3).分为了 8 组.
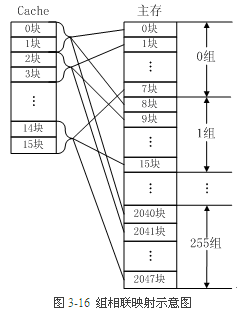
Intel 大多数处理器的L1 Cache都是32KB,8-Way 组相联,Cache Line 是64 Bytes。这意味着:
- L1 cache 32KB 最多加载 512 条 CacheLine. => 32KB / 64 = 512 条 Cache Line。=> 512 块.
- 8Way 组相联, L1 Cache 中 8 块一个组,如第 0 组(块 0…块 7), 共 64 组. => 512块/8块 =64组.
那么
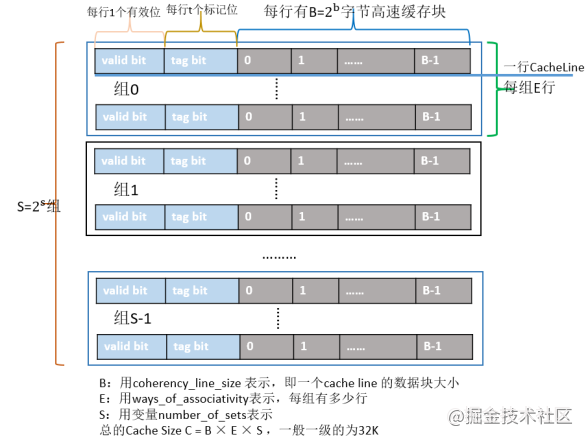
- L1 整个Cache被分为 S (S=64)个组
- 每个组是又由E (E=8)个最小的存储单元——Cache Line所组成
- 一个Cache Line中有B(B=64)个字节用来存储数据,即每个Cache Line能存储64个字节的数据
- 每个Cache Line又额外包含
- 一个有效位(valid bit),valid bit用来表示该缓存行是否有效;
- t个标记位(tag bit),tag bit用来协助寻址,唯一标识存储在CacheLine中的块;
- Cache Line里的64个字节其实是对应内存地址中的数据拷贝。
- 推算出每一级Cache的大小为B×E×S。=> 64*8*64=32KB
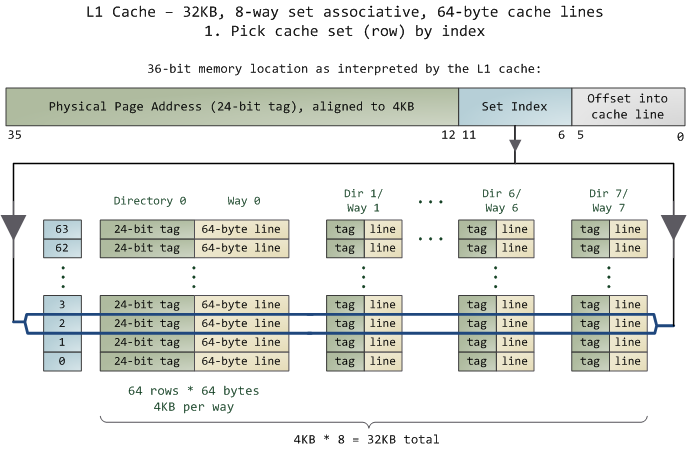
- L1 共 64 组, 因此组索引为 0~63, 组索引
set index需要 6bits. - 组内采用全相联映射
- 进行O(n) n=8 的遍历,主是要匹配前24bits的tag
- 如果匹配中了,就算命中
- 如果没有匹配到,那就是cache miss,
- 通过
set index+tag,L1 可以映射 2^30=1GB 的CacheLine. - offset into cache line
- 一个内存地址对应一个字节(Byte): 0xFF 或者说 8-bit.
- CacheLine 64 bytes,因此
offset into cache line需要 6 个 bit
缓存的一致性
如果有一个数据 x 在 CPU 第0核的缓存上被更新了,那么其它CPU核上对于这个数据 x 的值也要被更新
对于主流的CPU来说,缓存的写操作基本上是两种策略
- 一种是Write Back,写操作只要在cache上,然后再flush到内存上。
- 一种是Write Through,写操作同时写到cache和内存上。
为了提高写的性能,一般来说,主流的CPU(如:Intel Core i7/i9)采用的是Write Back的策略,因为直接写内存实在是太慢了。
cpu 硬件有两种方法解决这个问题:
- Directory 协议
- 设计一个集中式控制器,它是主存储器控制器的一部分
- Directory协议是一个中心式的,会有性能瓶颈,而且会增加整体设计的复杂度。
- Snoopy 协议
- 像是一种数据通知的总线型的技术。
- CPU Cache通过这个协议可以识别其它Cache上的数据状态。
- 如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。
状态协议
- Modified:这条cache line已被修改,其数据与主存中不一致,被标记为Modified的cache line在被驱逐时,需要把数据刷回到主存中
- Shared:这条cache line与主存中的数据是一致的,并且至少在一个核心中存在,这条cache line的数据在被驱逐时无需做额外操作
- Invalid:这块数据不存在,需要重新从主存中读取
表示缓存数据有四个状态
- Modified(已修改)
- 在这条cache line被回写到内存之前,禁止对内存中这条数据的read操作。
- 在被回写到内存中之后,这条cache line被标记为Exclusive。
- Exclusive(独占的)
- 这条cache line只在当前cache中存在(独享),这条cache line的数据与主存中一致。
- 如果这条cache line被其他cache读取,Exclusive会转为Shared。
- 如果发生写入,Exclusive会转换为Modified
- Shared(共享的)
- Invalid(无效的)
MESI 这种协议在数据更新后,会标记其它共享的CPU缓存的数据拷贝为Invalid状态,然后当其它CPU再次read的时候,就会出现 cache miss 的问题,此时再从内存中更新数据。
缺点
从内存中更新数据意味着20倍速度的降低。
MOESI 协议
MOESI协议允许 CPU Cache 间同步数据,于是也降低了对内存的操作,性能是非常大的提升,但是控制逻辑也非常复杂。
MESIF
MESIF,其中的 F 是 Forward,同样是把更新过的数据转发给别的 CPU Cache .
MESIF 中的 Forward 状态与MOESI 中的 Owner 状态区别:
- MOESI 中的 Owner状态下的数据是dirty的,还没有写回内存
-
MESIF 中的 Forward状态下的数据是clean的,可以丢弃而不用另行通知
AMD用MOESI,Intel用MESIF。所以,F 状态主要是针对 CPU L3 Cache 设计的